




1. Le problème du sac à dos▲
Le problème du sac à dos est un problème d'optimisation combinatoire dans lequel l'utilisateur dispose d'un ensemble d'objets auxquels sont associés un profit et un poids. L'objectif est de sélectionner un sous-ensemble de ces objets tel que la somme des profits soit maximale et qu'ils tiennent tous ensemble dans un conteneur d'une capacité donnée.
Dans la suite de cet article, les notations p[i], w[i] et W représenteront respectivement le profit apporté par l'objet numéroté i, son poids, et la capacité maximum du sac.
Ce problème est NP-difficile, ce qui signifie que nous ne connaissons pas d'algorithme polynomial permettant de le résoudre. Même si certains algorithmes résolvent des instances en des temps raisonnables, il existe des données pour lesquelles la résolution prendrait une éternité. En effet, dans le pire des cas, la résolution d'un tel problème avec n objets demanderait un nombre d'opérations de l'ordre de 2n.
L'exemple ci-dessous illustre la difficulté de trouver une solution optimale pour un tel problème, même pour un petit nombre d'objets.
1-1. Exemple de problème▲
Le décideur possède une bibliothèque musicale contenant dix titres. Le logiciel qu'il utilise pour gérer sa bibliothèque lui permet de donner une note comprise entre 1 et 5 à chaque titre, 5 étant la meilleure note. Les informations sur les titres sont récapitulées dans la table ci-dessous :
|
Numéro |
Titre |
Note |
Poids (octets) |
|
1 |
Cohiba Playa - Radiodays (ft. Dj Volto) |
4 |
4 000 000 |
|
2 |
Musetta - Ophelia's song |
4 |
5 200 000 |
|
3 |
Cartel - Real Talk by Brix |
2 |
2 700 000 |
|
4 |
Professor Kliq - Bust This Bust That |
5 |
6 800 000 |
|
5 |
The Dada Weatherman - Painted Dream |
5 |
8 000 000 |
|
6 |
Alexander Blu - Emptiness |
3 |
6 200 000 |
|
7 |
UltraCat - Disco High |
3 |
6 300 000 |
|
8 |
Josh Woodward - Effortless |
2 |
5 300 000 |
|
9 |
Tryad - Struttin' |
1 |
5 600 000 |
|
10 |
Silence - Cellule |
1 |
5 900 000 |
Son lecteur multimédia portable a une capacité de 16 000 000 octets. Il souhaite le remplir de manière à obtenir la meilleure liste de lecture possible à partir de sa bibliothèque. C'est-à-dire que la somme des notes des titres choisis doit être maximale.
Une approche naïve consiste à choisir les titres dans l'ordre décroissant de leurs notes, jusqu'à remplir le lecteur. La solution ainsi obtenue est constituée des titres numéro 4 et 5 et a une note totale de 10 pour un poids de 14 800 000 octets. Une autre approche intuitive est de choisir les titres dans l'ordre décroissant du rapport de leur note sur leur poids. La solution obtenue avec cette méthode est alors constituée des titres numéro 1, 2 et 3, avec une note à nouveau égale à 10, pour un poids cette fois égal à 11 900 000 octets.
Ces deux procédés donnent des solutions équivalentes, mais différentes. Cependant, aucune d'entre elles n'est optimale. Pour trouver une telle liste, il suffit de construire un problème de sac à dos où les objets sont les titres. Le cout d'un objet est la note associée au titre et son poids sa taille en octets. La capacité du sac est égale à la capacité du lecteur. Notre problème ainsi construit accepte une unique solution optimale composée des titres numéro 1, 2 et 4, avec une note de 13 pour un poids de 16 000 000 octets exactement.
2. Algorithmes pour la résolution de problèmes de sac à dos▲
La programmation dynamique est une approche générale qui se retrouve comme technique de résolution de problèmes. Cette technique peut être appliquée dès lors qu'une solution optimale consiste en une combinaison de solutions optimales de sous-problèmes, ce qui est le cas pour le sac à dos. En effet, la valeur optimale d'une instance de ce problème peut s'obtenir en considérant le maximum de deux situations sur le dernier objet, ici noté avec l'indice i :
- soit l'objet participe à la solution, auquel cas il ne laisse qu'une capacité égale à W-w[i] disponible pour les autres objets. La valeur de cette solution est alors égale à celle obtenue sur les autres objets avec cette capacité, plus le profit p[i] ;
- soit l'objet ne participe pas à la solution, auquel cas sa valeur est égale à celle obtenue avec les autres objets et la même capacité.
Ce procédé s'applique récursivement jusqu'à ne plus avoir d'objet à traiter. Dans ce dernier cas, la valeur optimale est égale à zéro. Bellman [1] a mis cela en équation ; de nombreux algorithmes se sont basés dessus par la suite.
Nous représenterons les données associées à un objet avec la structure ci-dessous :
/**
* \brief Un objet du problème, pour programmation classique.
*/
struct kp_item
{
kp_item( unsigned int p, unsigned int w )
: profit(p), weight(w)
{ }
unsigned int profit;
unsigned int weight;
};Une implémentation directe de la procédure récursive est alors la suivante :
/**
* \brief Calcul de la valeur optimale d'un problème de sac à dos, par
* application directe des équations de Bellman.
* \param data Les données des objets.
* \param d La capacité du sac.
* \param n Le nombre d'objets considérés.
*/
unsigned int solve_kp
( const std::vector<kp_item>& data, unsigned int d, unsigned int n )
{
if (n==0) // pas d'objet ?
return 0; // la solution est vide
else
{
// Nous allons considérer le dernier objet, dont les données sont dans la
// case n-1 des vecteurs
const unsigned int i(n-1);
// Si l'objet i ne rentre pas dans le sac, il ne peut pas être choisi. La
// valeur de la solution est donc obtenue en considérant les autres
// objets, en gardant la même capacité.
if (data[i].weight > d)
return solve_kp(data, d, n-1);
else
// Si l'objet i tient dans le sac, il y a deux possibilités. Soit il
// participe à la solution d'une valeur p[i], auquel cas il ne
// reste qu'une capacité de d - w[i] pour les autres objets. Soit il ne
// participe pas à la solution, auquel cas la capacité est
// inchangée. La valeur de la solution optimale est obtenue en gardant
// la meilleure de ces deux solutions.
return std::max
( solve_kp(data, d-data[i].weight, n-1) + data[i].profit,
solve_kp(data, d, n-1) );
}
}Nous pouvons remarquer que la procédure ci-dessus peut résoudre des sous-problèmes identiques à plusieurs reprises. Par exemple, si les deux premiers objets considérés ont le même poids w', alors les appels récursifs solve_kp(data, d-w[i], n-1) et solve_kp(data, d, n-1) vont tous les deux effectuer un appel à solve_kp(data, d - w', n-2). Or, le résultat de cet appel sera identique dans les deux cas. La figure 1 illustre ces appels récursifs et met en évidence cette répétition.

Figure 1. Les appels récursifs donnent lieu à de multiples résolutions d'un même sous-problème. Nous supposons ici que les deux premiers objets considérés ont le même poids w', les sous-problèmes colorés sont alors identiques.
Bien sûr, il est inefficace de résoudre le même sous-problème à plusieurs reprises. Par conséquent, nous aimerions que la valeur optimale pour le sous-problème avec n - 2 variables et une capacité égale à d - w' ne soit calculée qu'une fois. La programmation dynamique apporte une réponse à cette difficulté. Il existe de nombreux algorithmes utilisant cette approche pour le sac à dos. Cependant, nous ne nous intéresserons qu'à la programmation dynamique dite par listes dans la suite de cet article.
2-1. Programmation dynamique par listes▲
L'algorithme présenté dans cette section est tiré d'un ouvrage de Martello et Toth [2]. Il consiste à maintenir une liste de sous-problèmes associés à la valeur optimale de leurs solutions. Cette association représente un état. L'algorithme met cette liste à jour en considérant les objets un à un.
Comme le suggère l'arbre de la figure 1, un sous-problème est défini par une capacité disponible et un ensemble d'objets restant à considérer. Nous associons également à un état la valeur des solutions optimales du sous-problème. La structure suivante représente un tel état :
/**
* \brief Un état de la programmation dynamique.
*/
struct state
{
/** Le meilleur profit pouvant être obtenu à cet état. */
unsigned int profit;
/** La capacité restante dans le sac. */
unsigned int remaining_capacity;
state( unsigned int p, unsigned int r )
: profit(p), remaining_capacity(r)
{ }
};Nous pouvons remarquer que les objets disponibles ne sont pas représentés dans cette structure. En effet, à chaque itération de l'algorithme, tous les états en mémoire auront la même liste d'objets. Il est donc inutile de stocker cette information.
L'algorithme de calcul des états débute par la construction d'un état de départ. Initialement, la capacité disponible est égale à W, aucun objet n'est utilisé et le plus grand profit est donc égal à zéro. Cet état est alors state(0, W). Le premier objet est ensuite considéré selon deux situations. Soit il participe à la solution, donnant lieu au nouvel état state(p[0], W - w[0]), soit il n'y participe pas, auquel cas l'état state(0, W) est conservé. Nous avons alors une liste de deux états pouvant être atteints avec le premier objet. Le deuxième objet est ensuite considéré à partir de ces états, donnant lieu à une nouvelle liste remplaçant l'initiale. Le procédé est répété pour tous les objets. À la ie itération, une liste L d'états représentant les sous problèmes obtenus avec les i-1 premiers objets est parcourue. L'objet i est alors utilisé pour créer les états des sous-problèmes avec i objets. La liste L est ensuite remplacée par les nouveaux états obtenus.
Si plusieurs états ont la même capacité disponible, seul celui avec le plus grand profit est conservé. De plus, si la liste contient deux états s1 et s2 tels que le profit du second est supérieur au profit du premier, et tels que la capacité restante dans le second soit aussi supérieure à celle du premier, alors seul s2 est conservé. En effet, il apporte un plus grand profit tout en laissant plus de place pour les objets restants. Comme ces objets sont les mêmes dans les deux cas, il est certain que le premier n'amènera pas à une solution optimale.
La procédure calculant la liste obtenue en ajoutant un objet à partir d'une liste initiale d'états est présentée ci-dessous :
/**
* \brief Cette fonction construit la liste des états obtenus en considérant la
* sélection ou la non-sélection d'un objet à partir d'une liste d'états
* donnée. Le résultat est une liste d'états dont le profit est le
* maximum obtenu selon la sélection.
* \param data La donnée de l'objet considéré.
* \param state_list (entrée/sortie) La liste des états à étendre.
*/
void add_item( const kp_item& data, std::list<state>& state_list )
{
std::list<state> new_list;
std::list<state>::iterator it;
// on crée une nouvelle liste où l'objet est ajouté
for (it=state_list.begin(); it!=state_list.end(); ++it)
if (it->remaining_capacity >= data.weight )
new_list.push_back
( state
( it->profit + data.profit, it->remaining_capacity - data.weight ) );
else
break;
// puis on fusionne la nouvelle liste et l'ancienne en gardant l'état avec le
// plus grand profit quand deux états ont la même capacité restante.
// Nous commençons par stocker la liste initiale dans old_list et par vider
// state_list pour la préparer à recevoir les états résultant de la fusion.
std::list<state> old_list;
std::swap(old_list, state_list);
/**
* Nous allons parcourir en parallèle la nouvelle liste et l'ancienne. Elles
* sont ordonnées selon la capacité restante décroissante et il en sera de
* même pour la liste retournée. Par conséquent, trois cas se présentent
* durant le parcours :
*
* # Les états en tête des deux listes ont la même capacité restante. Nous
* construisons donc un nouvel état avec la même capacité et un profit égal
* au max des profits des deux états. Nous continuons ensuite le traitement
* sur les restes des deux listes.
* # L'état en tête de la première liste a une capacité restante supérieure à
* celle de l'état en tête de la seconde liste. Nous ajoutons donc ce
* premier état à la liste résultat puis nous fusionnons le reste de la
* première liste avec toute la seconde liste.
* # L'état en tête de la seconde liste a une capacité restante supérieure à
* celle de l'état en tête de la première liste. Nous ajoutons donc ce
* premier état à la liste résultat puis nous fusionnons toute la première
* liste avec le reste de la seconde liste.
*
* La variable best est mise à jour durant le parcours avec le plus grand
* profit obtenu depuis le début du traitement. Si un nouvel état a un profit
* inférieur à cette valeur, il est ignoré. En effet, comme les états sont
* ordonnés par capacité restante décroissante, il existe nécessairement un
* autre état avec un profit meilleur (égal à best) et un plus grand espace
* disponible pour les objets restants.
*/
unsigned int best(0);
while ( !old_list.empty() && !new_list.empty() )
{
state new_state(0, 0);
if ( old_list.front().remaining_capacity
== new_list.front().remaining_capacity )
{
new_state =
state
( std::max(old_list.front().profit, new_list.front().profit),
old_list.front().remaining_capacity);
old_list.pop_front();
new_list.pop_front();
}
else if ( old_list.front().remaining_capacity
> new_list.front().remaining_capacity )
{
new_state = old_list.front();
old_list.pop_front();
}
else
{
new_state = new_list.front();
new_list.pop_front();
}
if ( new_state.profit >= best )
{
best = new_state.profit;
state_list.push_back(new_state);
}
}
// une seule des deux boucles ci-dessous sera effectuée, au plus
for ( ; !old_list.empty(); old_list.pop_front() )
if ( old_list.front().profit >= best )
{
best = old_list.front().profit;
state_list.push_back(old_list.front());
}
for ( ; !new_list.empty(); new_list.pop_front() )
if ( new_list.front().profit >= best )
{
best = new_list.front().profit;
state_list.push_back(new_list.front());
}
}Il suffit ensuite d'appeler la fonction add_item() sur chaque objet pour mettre à jour la liste des états et calculer la valeur des solutions optimales. La procédure de résolution est décrite ci-dessous :
/**
* \brief Résolution d'un problème de sac à dos.
* \param data Les données des objets.
* \param W La capacité du sac.
* \return La valeur des solutions optimales.
*/
unsigned int dp_kp
( const std::vector<kp_item>& data, unsigned int W )
{
// La liste des états.
std::list<state> L;
L.push_back( state(0, W) );
// Nous ajoutons les objets un à un.
for (std::size_t i=0; i!=data.size(); ++i)
add_item( data[i], L );
// Avec le filtrage des états effectué dans add_item(), le dernier état a
// nécessairement le plus grand profit.
return L.back().profit;
}3. Implémentation par métaprogrammation▲
La métaprogrammation est une technique qui consiste à effectuer des manipulations sur les structures décrivant un programme de manière à générer du code ou à faire effectuer des calculs par le compilateur, lorsque toutes les données sont disponibles au moment de la compilation. C'est une approche qui utilise grandement les patrons de classe. Le lecteur intéressé pourra s'orienter vers cet article pour de nombreux exemples et par exemple vers la bibliothèque Loki pour de nombreuses applications.
En pratique, nous allons utiliser les patrons de classe comme un langage fonctionnel qui agit lors de la compilation, ce qui implique certaines contraintes. En effet, nous manipulons des types et non pas des instances de classes. Nous ne pourrons donc pas initialiser nos données via un constructeur ni effectuer d'affectation ; nous ne pouvons que définir de nouveaux types, jamais en remplacer.
Considérons par exemple le type suivant, qui représentera les données d'un objet du sac à dos dans le cadre de la métaprogrammation :
/**
* \brief Un objet du problème.
* \param Profit Le profit associé à l'objet.
* \param Weight Le poids associé à l'objet.
*/
template<unsigned int Profit, unsigned int Weight>
struct item
{
static const unsigned int profit = Profit;
static const unsigned int weight = Weight;
};Si nous comparons cette structure à kp_item, présentée dans la section 2, nous constatons que les paramètres du constructeur sont devenus des paramètres du patron. En réalité, pour le compilateur, ces données définiront un type basé sur le modèle item<>. Nous utiliserons ce type pour stocker nos données. Il en sera de même pour la structure représentant un état de la programmation dynamique :
/**
* \brief Un état de la programmation dynamique.
* \param Profit Le meilleur profit pouvant être obtenu à cet état.
* \param RemainingCapacity La capacité restante dans le sac.
*/
template<unsigned int Profit, unsigned int RemainingCapacity>
struct state
{
static const unsigned int profit = Profit;
static const unsigned int remaining_capacity = RemainingCapacity;
};Comme pour n'importe quel autre type, nous ne pourrons lui en « attribuer » un autre. Ainsi, lorsque nous calculerons les états obtenus depuis un état donné, en considérant qu'un objet est sélectionné ou non, nous déclarerons un nouveau type basé sur state<> et dont les valeurs des paramètres exprimeront la sélection éventuelle de l'objet.
En plus de ces limitations, nous n'aurons pas non plus un accès immédiat aux instructions classiques de branchement telles que la conditionnelle ou les boucles. En pratique, nous remplacerons la première par un patron de classe spécialisé selon la valeur de la condition (voir la section 3.1.2) et nous utiliserons un procédé récursif lorsque nous aurons besoin d'effectuer un traitement itératif.
La section suivante présente deux structures classiques de la métaprogrammation ainsi que des approches algorithmiques qui y sont associées. Ces structures seront utilisées dans la section 3.2, où l'algorithme récursif de résolution de problèmes de sac à dos sera implémenté, puis dans la section 3.3, où la programmation dynamique sera à son tour implémentée.
3-1. Structures classiques de métaprogrammation▲
Cette section présente deux structures classiques de métaprogrammation que nous utiliserons pour le sac à dos. Des exemples d'algorithmes utilisant ces structures sont donnés pour illustrer les calculs récursifs et la définition conditionnelle de type.
3-1-1. Liste de types▲
Un exemple classique d'application de la métaprogrammation se trouve dans les listes de types, définies comme suit :
/**
* \brief Une liste de types.
* \param Head Le premier type dans la liste.
* \param Tail La suite de la liste.
*/
template<typename Head, typename Tail>
struct type_list
{
typedef Head head;
typedef Tail tail;
};Cette structure permet de construire une liste chaînée de types ou de données en utilisant des énumérations ou des constantes statiques. Le type Head représente le premier élément de la liste tandis que Tail contient les autres éléments. En général, ce dernier est soit une structure de type type_list, soit une structure représentant une liste vide. Par exemple :
/** \brief Un type vide que l'on utilisera pour marquer la fin d'une liste de
types. */
struct empty_list {};Ce dernier type va nous permettre de mettre fin à un traitement effectué sur chaque élément de la liste. Le lecteur intéressé pourra s'orienter vers ce billet en anglais.
3-1-1-1. Exemple d'algorithme : calcul de la longueur d'une liste de types▲
La structure ci-dessous permet de calculer le nombre d'éléments dans une liste de types nommée TypeList passée en paramètre au patron. L'idée est la suivante : s'il s'agit d'une liste vide, elle contient zéro élément. Sinon, elle contient l'élément TypeList::head plus le nombre d'éléments dans TypeList::tail.
/**
* \brief Calcul du nombre d'éléments dans une liste de types.
* \param TypeList La liste des types.
*
* L'algorithme correspondant à ce calcul peut s'écrire :
* fonction length(L : liste) : entier
* variables
* result : entier
* début
* si L == liste_vide alors
* result = 0
* sinon
* result = 1 + length( suite(L) )
* finsi
*
* retourner result
* fin
*
* Cette prédéclaration est en quelque sorte la signature de
* la fonction.
*/
template<typename TypeList>
struct length;
/**
* \brief Spécialisation pour une liste vide. Il s'agit en
* quelque sorte de la condition d'arrêt des
* « appels » récursifs de la structure précédente.
*/
template<>
struct length<empty_list>
{
static const unsigned int result = 0;
};
/** Spécialisation pour le cas d'une liste ayant au moins un
élément. */
template<typename Head, typename Tail>
struct length< type_list<Head, Tail> >
{
// Remarquons que l'appel récursif de l'algorithme se traduit par
// l'utilisation répétée de cette structure.
static const unsigned int result =
1 + length<typename Tail>::result;
};Remarquons que nous aurions pu utiliser une énumération pour stocker la valeur de result. En pratique, la différence est faible. Il faut néanmoins savoir que certains compilateurs n'acceptent pas cette initialisation de constante, même statique, dans le corps de la classe. Néanmoins, nous aurons besoin par la suite d'effectuer des comparaisons d'ordre sur des constantes de ce type. Or, l'utilisation d'énumération entraîne des avertissements du compilateur, tandis que des constantes statiques sont comparables sans ambiguïtés. Pour cette raison et par souci d'uniformité, toutes nos données seront représentées par des constantes statiques.
3-1-2. Déclaration conditionnelle de type▲
Un autre exemple récurrent de métaprogrammation est l'utilisation d'une structure if_then_else pour effectuer des définitions conditionnelles de types. Elle prend en paramètre une valeur booléenne et deux types. Selon la valeur du booléen, le résultat est soit le premier type, soit le second. Cette structure se présente comme suit :
/**
* \brief Cette structure effectue un typedef sur l'un des deux types passés en
* paramètres, selon la valeur d'un booléen.
* \param B Le booléen à évaluer.
* \param T1 Le type sur lequel est fait le typedef quand B est vrai.
* \param T2 Le type sur lequel est fait le typedef quand B est faux.
*/
template<bool B, typename T1, typename T2>
struct if_then_else;
/** \brief Spécialisation pour le cas où le booléen est vrai. */
template<typename T1, typename T2>
struct if_then_else<true, T1, T2>
{
typedef T1 result;
};
/** \brief Spécialisation pour le cas où le booléen est faux. */
template<typename T1, typename T2>
struct if_then_else<false, T1, T2>
{
typedef T2 result;
};3-1-2-1. Exemple d'algorithme : filtrer une liste d'états▲
Supposons que nous connaissions une liste d'états de la programmation dynamique et que nous souhaitions ne conserver que ceux dont le profit est au-dessus d'un certain seuil. Nous allons déclarer une structure effectuant cette séparation. Elle prend en paramètres le seuil et la liste des états, puis définit un type result selon ces paramètres. Si le premier état de la liste a un profit inférieur à ce seuil, alors il est ignoré et le résultat est celui du traitement sur les états restants. Sinon, le résultat est une liste dont le premier élément est ce premier état et dont les autres éléments sont le résultat de ce même traitement sur les états restants :
/**
* \brief Récupère les états dont le profit est au-dessus d'un certain seuil.
* \param S Le seuil des profits.
* \param StateList La liste des états à filtrer.
*
* L'algorithme correspondant à ce calcul peut s'écrire :
* fonction filter(S : entier, L : liste) : liste
* variables
* result : liste
* début
* si L == liste_vide alors
* result = liste_vide
* sinon si tête(L).profit < S alors
* result = filter(S, suite(L))
* sinon
* result = (tête(L), filter(S, suite(L)))
* finsi
*
* retourner result
* fin
*/
template<unsigned int S, typename StateList>
struct filter;
/** \brief Spécialisation pour une recherche dans une liste vide. */
template<unsigned int S>
struct filter<S, empty_list>
{
typedef empty_list result;
};
/** Spécialisation pour le cas d'une liste ayant au moins un
élément. */
template<unsigned int S, typename Head, typename Tail>
struct filter<S, type_list<Head, Tail> >
{
typedef typename filter<S, Tail>::result new_tail;
typedef typename
if_then_else< (Head::profit < S),
new_tail,
type_list<Head, new_tail> >::result result;
};Sur certains compilateurs, la condition donnée ici pour le if_then_else ne sera pas acceptée. Il faudra alors passer par une structure annexe effectuant la comparaison. Par exemple :
template<unsigned int A, unsigned int B>
struct is_less
{
static const bool result = (A<B);
};3-2. Implémentation de l'algorithme récursif pour le sac à dos▲
Cette section présente un équivalent à l'algorithme solve_kp() de la section 2. Du fait du caractère récursif de cette procédure, la conversion se fait aisément.
Nous allons définir un patron de classe nommé solve_kp<> prenant deux paramètres. Le premier sera un entier représentant la capacité disponible dans le sac et le second sera un type_list contenant des types item auxquels seront indiqués le profit et le poids des objets. Le premier élément de cette liste sera considéré et un traitement récursif sera effectué sur le reste de la liste, éventuellement avec une autre capacité disponible. Comme pour la structure length présentée dans la section 3.1.1.1, effectuer un appel récursif consiste à faire une nouvelle instanciation du même patron, avec des paramètres différents. À nouveau, une spécialisation est faite pour le cas d'une liste vide, afin de stopper la récursivité. Le résultat du calcul sera stocké dans une constante statique nommée result. Nous pouvons déjà prédéclarer le patron solve_kp<> et effectuer la spécialisation :
/**
* \brief Une classe qui résout un problème de sac à dos en utilisant les
* équations de Bellman. La valeur optimale du problème est stockée dans
* une constante membre statique nommée result.
* \param RemainingCapacity La capacité restante dans le sac.
* \param ItemList Les objets sur lesquels nous faisons une sélection.
*/
template<unsigned int RemainingCapacity, typename ItemList>
struct solve_kp;
/**
* \brief Spécialisation pour le cas d'une liste vide d'objets. Quelle que soit
* la capacité, la valeur de la solution est zéro.
*/
template<unsigned int RemainingCapacity>
struct solve_kp<RemainingCapacity, empty_list>
{
static const unsigned int result = 0;
};Il ne nous reste plus qu'à effectuer le calcul de la valeur optimale des solutions. Pour cela, nous reprenons les trois cas considérés dans la procédure solve_kp(). Si l'objet traité ne rentre pas dans le sac, le résultat est un appel récursif avec la même capacité et avec les objets restants. Sinon, il est égal au maximum obtenu en considérant que l'objet est sélectionné ou non. Nous utilisons la structure suivante pour obtenir le maximum de deux valeurs :
/**
* \brief Cette structure définit une constante ayant pour valeur le maximum des
* deux valeurs passées en paramètres.
* \param A La première valeur.
* \param B La seconde valeur.
*/
template<unsigned int A, unsigned int B>
struct max_value
{
static const unsigned int result = (A>B) ? A : B;
};L'écriture du patron de classe solve_kp<> est ensuite assez directe. La conditionnelle de la procédure initiale est remplacée par l'opérateur ternaire ?: pouvant être utilisé dans la déclaration de valeurs constantes :
/* Déclaration complète. */
template<unsigned int RemainingCapacity, typename ItemList>
struct solve_kp
{
typedef typename ItemList::head head;
typedef typename ItemList::tail tail;
/* Notons l'utilisation répétée de solve_kp<> pour remplacer les appels
récursifs de l'algorithme initial. */
static const unsigned int result =
(head::weight > RemainingCapacity) ?
solve_kp<RemainingCapacity, tail>::result :
max_value
<
solve_kp<RemainingCapacity, tail>::result,
solve_kp<RemainingCapacity - head::weight, tail>::result + head::profit
>::result;
};Remarquons que les objets sont considérés ici dans l'ordre où ils apparaissent dans la liste, contrairement à la procédure initiale solve_kp() où ils étaient traités du dernier au premier. En pratique, l'ordre des objets n'a aucune influence sur la valeur optimale des solutions. Cela ne change donc absolument pas la validité du calcul.
Le code ci-dessous illustre l'utilisation du patron solve_kp<> pour calculer la valeur du problème présenté dans la section 1.1. Pour plus de lisibilité, les poids et la capacité du sac ont été divisés par 100 000 :
// définition de la liste des objets
typedef
type_list< item<4, 40>,
type_list< item<4, 52>,
type_list< item<2, 27>,
type_list< item<5, 68>,
type_list< item<5, 80>,
type_list< item<3, 62>,
type_list< item<3, 63>,
type_list< item<2, 53>,
type_list< item<1, 56>,
type_list< item<1, 59>,
empty_list
>
>
>
>
>
>
>
>
>
>
kp;
// le calcul de la valeur optimale est effectué ici
std::cout << "result=" << solve_kp<160, kp>::result << '\n'
<< std::endl;3-3. Implémentation de la programmation dynamique par listes▲
Le caractère récursif de la procédure solve_kp() profite grandement à sa conversion vers le patron de classe solve_kp<>. Malheureusement, l'algorithme de programmation dynamique ne possède pas ce caractère. L'implémentation de ce dernier a été faite avec deux procédures que nous détaillons dans la suite de cette section. La conversion de la procédure add_item() est présentée en premier. Nous détaillons ensuite l'itération sur la liste des objets effectuée dans la procédure dp_kp(). Enfin, la dernière section présente le calcul de la valeur optimale des solutions en utilisant ces patrons de classe.
3-3-1. Conversion de la procédure add_item()▲
La nouvelle liste d'états obtenue par la considération d'un objet est calculée en trois étapes. Comme nous l'avons indiqué précédemment, nous ne pouvons pas effectuer d'affectation. Chaque opération sur une liste d'états donnera donc lieu à une nouvelle liste.
Les trois étapes sont les suivantes. Tout d'abord, une seconde liste est définie à partir de la première en ajoutant l'objet depuis tous les états ayant une capacité suffisante. Une troisième liste est ensuite définie comme étant la fusion de la seconde avec la première, en ne gardant que le meilleur profit pour deux états ayant la même capacité restante. Enfin, une quatrième liste d'états est définie à partir de cette dernière, en supprimant les états clairement inefficaces.
La suite de cette section présente chacune de ces étapes. Comme pour l'algorithme initial, nous maintenons la liste des états dans l'ordre décroissant de la capacité restante tout au long de la résolution.
3-3-1-1. Extension de la liste des états en ajoutant un objet▲
L'extension de la liste des états prend en paramètre un objet nommé Item et une liste d'états StateList initiale. Une nouvelle liste est construite de la manière suivante : le premier état est obtenu en ajoutant l'objet depuis le premier état de la liste. Il s'agit de définir un nouvel état en utilisant le patron state<> pour lequel le profit est la somme de celui de l'état initial avec celui de l'objet et la capacité résiduelle est celle de l'état initial diminuée du poids de l'objet. Dans le code, ce nouvel état s'écrit state<StateList::head::profit + Item::profit, StateList::head::remaining_capacity - Item::weight>. Le reste de la nouvelle liste est ensuite obtenu en effectuant le même traitement sur le reste de la liste initiale.
Bien sûr, si la capacité restante de l'état considéré est plus petite que le poids de l'objet, alors cet objet ne peut être ajouté. De plus, comme la liste initiale est triée selon la capacité restante décroissante, il ne pourra pas non plus être ajouté depuis un état du reste de la liste. Par conséquent, dans ce cas, la liste résultante sera une liste vide.
Le traitement complet est détaillé par le code ci-dessous. Nous vérifions que l'objet peut être ajouté depuis l'état en tête et nous définissons la liste résultante selon ce critère.
/**
* \brief Cette structure ajoute un objet dans tous les états d'une liste
* d'états. Le résultat est une liste d'états représentée par une
* définition de type nommée result.
* \param Item L'objet ajouté.
* \param StateList La liste des états.
*
* En notant StateList = ( (p1, w1), (p2, w2), ..., (pk, wk) ), cette structure
* construit la liste des états (pi+Item::profit, wi-Item::weight) pour tout i
* tel que wi soit supérieur à Item::weight.
*/
template<typename Item, typename StateList>
struct add_item_to_all;
/**
* \brief Spécialisation pour une liste vide, le résultat est une liste vide.
*/
template<typename Item>
struct add_item_to_all<Item, empty_list>
{
typedef empty_list result;
};
/* Déclaration complète. */
template<typename Item, typename Head, typename Tail>
struct add_item_to_all< Item, type_list<Head, Tail> >
{
typedef typename
if_then_else
<
is_less_equal<Item::weight, Head::remaining_capacity>::result,
type_list
<
// On crée l'état obtenu à partir du premier de StateList.
state< Head::profit + Item::profit,
Head::remaining_capacity - Item::weight>,
// puis on recommence le traitement sur le reste de la liste.
typename add_item_to_all
<
Item,
Tail
>::result
>,
empty_list // la liste des états est ordonnée selon la capacité restante
// décroissante. Par conséquent, si cet objet ne peut être ajouté à
// un état, il est inutile d'essayer de l'ajouter aux suivants.
>::result result;
};3-3-1-2. Fusion de deux listes d'états▲
La deuxième étape de la procédure d'ajout d'un objet consiste à fusionner la liste initiale des états avec celle obtenue via la structure add_item_to_all. Cette fusion se fait d'une manière similaire à celle décrite dans la section 2.1. Nous considérons deux listes d'états, ordonnés selon leur capacité restante décroissante. Ces deux listes sont parcourues en parallèle pour créer une troisième liste où seul le meilleur état est conservé pour une capacité restante donnée. Cette structure est définie ci-dessous :
/**
* \brief Cette structure fusionne des listes d'états en gardant le max des
* profits pour une capacité donnée. Le résultat est une liste d'états
* représentée par une définition de type nommée result.
* \param StateList1 La première liste, à fusionner avec la seconde.
* \param StateList2 La seconde liste, à fusionner avec la première.
*/
template<typename StateList1, typename StateList2>
struct merge_state_lists;
/* Déclaration complète */
/**
* Nous allons parcourir en parallèle les listes passées en paramètres. Elles
* sont ordonnées selon la capacité restante décroissante et il en sera de même
* pour la liste retournée. Par conséquent, trois cas se présentent durant le
* parcours :
*
* # Les états en tête des deux listes ont la même capacité restante. Nous
* construisons donc un nouvel état avec la même capacité et un profit égal au
* max des profits des deux états. Nous continuons ensuite le traitement sur
* les restes des deux listes.
* # L'état en tête de la première liste a une capacité restante supérieure à
* celle de l'état en tête de la seconde liste. Nous ajoutons donc ce premier
* état à la liste résultat puis nous fusionnons le reste de la première liste
* avec toute la seconde liste.
* # L'état en tête de la seconde liste a une capacité restante supérieure à
* celle de l'état en tête de la première liste. Nous ajoutons donc ce premier
* état à la liste résultat puis nous fusionnons toute la première liste avec
* le reste de la seconde liste.
*/
template<typename Head1, typename Tail1, typename Head2, typename Tail2>
struct merge_state_lists< type_list<Head1, Tail1>, type_list<Head2, Tail2> >
{
typedef typename
if_then_else
<
is_equal<Head1::remaining_capacity, Head2::remaining_capacity>::result,
type_list
<
state
<
max_value<Head1::profit, Head2::profit>::result,
Head1::remaining_capacity
>,
typename merge_state_lists<Tail1, Tail2>::result
>,
typename if_then_else
<
is_less<Head2::remaining_capacity, Head1::remaining_capacity>::result,
type_list
<
Head1,
typename merge_state_lists< Tail1, type_list<Head2, Tail2> >::result
>,
type_list
<
Head2,
typename merge_state_lists< type_list<Head1, Tail1>, Tail2 >::result
>
>::result
>::result result;
};La récursivité s'effectue sur deux listes, nous allons donc devoir faire une spécialisation pour le cas d'une liste vide pour chacune d'elles :
/**
* \brief Spécialisation pour le cas où la première liste est vide. Le résultat
* est la seconde liste.
*/
template<typename StateList>
struct merge_state_lists<empty_list, StateList>
{
typedef StateList result;
};
/**
* \brief Spécialisation pour le cas où la seconde liste est vide. Le résultat
* est la première liste.
*/
template<typename StateList>
struct merge_state_lists<StateList, empty_list>
{
typedef StateList result;
};Cependant, si nous laissons le code comme cela, le compilateur ne saura pas quel patron instancier lorsque les deux listes sont vides simultanément. Nous devons donc déclarer une troisième spécialisation pour ce cas :
/**
* \brief Spécialisation pour le cas où les deux listes sont vides, pour lever
* l'ambiguïté des spécialisations précédentes. Le résultat est une liste
* vide.
*/
template<>
struct merge_state_lists<empty_list, empty_list>
{
typedef empty_list result;
};3-3-1-3. Suppression des états inefficaces▲
La dernière étape du calcul de la nouvelle liste d'états dans la programmation dynamique est la suppression des états les plus mauvais. Cette étape s'écrit d'une manière similaire au patron filter<> présenté dans la section 3.1.2.1, à ceci près que le seuil est mis à jour au fur et à mesure que nous avançons dans la liste :
/**
* \brief Crée une liste ou les états les plus mauvais sont supprimés. Le
* résultat est une liste d'états représentée par une définition de
* type nommée result.
* \param Best La meilleure valeur connue.
* \param StateList La liste à traiter.
*/
template<unsigned int Best, typename StateList>
struct clear_list;
/**
* \brief Spécialisation pour le cas où la liste est vide.
*/
template<unsigned int Best>
struct clear_list<Best, empty_list>
{
typedef empty_list result;
};
/* Déclaration complète */
/**
* L'idée est la suivante : si la liste contient deux états s(p1, w1) et
* s(p2, w2) tels que w1 > w2 et p1 > p2, alors le premier est clairement
* meilleur que le second. En effet, il laisse plus d'espace disponible et a un
* profit plus grand.
*
* La liste est initialement ordonnée par ordre décroissant de capacité
* restante, la sélection est alors aisée.
*/
template<unsigned int Best, typename Head, typename Tail>
struct clear_list< Best, type_list<Head, Tail> >
{
typedef typename
if_then_else
<
is_less<Head::profit, Best>::result,
typename clear_list<Best, Tail>::result,
type_list<Head, typename clear_list<Head::profit, Tail>::result>
>::result result;
};3-3-1-4. Implémentation du patron remplaçant add_item()▲
Nous avons maintenant tous les éléments pour écrire un patron de classe add_item<> effectuant les calculs équivalents à la procédure add_item(). Ce patron prend en paramètre un objet et une liste d'états. Il définit alors la liste des états obtenus en considérant que l'objet est ajouté ou pas. Cette liste est construite en supprimant les états inefficaces dans celle résultant de la fusion de la liste initiale avec celle obtenue en ajoutant l'objet. En pratique, nous écrivons cela comme suit :
/**
* \brief Cette structure construit la liste des états obtenus en considérant la
* sélection ou la non-sélection d'un objet à partir d'une liste d'états
* donnée. Le résultat est une liste d'états dont le profit est le
* maximum obtenu selon la sélection, représentée par une définition de
* type nommée result.
* \param Item L'objet considéré.
* \param StateList La liste des états à étendre.
*
* La liste donnée en paramètre n'est pas modifiée lorsque l'objet n'est pas
* sélectionné. Nous construisons la liste obtenue par l'ajout de l'objet en
* utilisant add_item_to_all, puis nous fusionnons le résultat avec la liste
* initiale en utilisant merge_state_lists.
*/
template<typename Item, typename StateList>
struct add_item
{
typedef
typename clear_list
<
0,
typename merge_state_lists
< StateList,
typename add_item_to_all<Item, StateList>::result
>::result
>::result result;
};Contrairement aux algorithmes précédents, celui-ci n'est pas récursif. De plus, la liste passée en paramètre devrait au moins contenir un état. Par conséquent, nous ne faisons pas de spécialisation pour le cas d'une liste vide.
3-3-2. Conversion de la procédure dp_kp()▲
La procédure dp_kp() met à jour une liste d'états en considérant les objets un à un puis retourne le plus grand profit dans la liste finale. Nous allons déclarer un patron de classe pour chacune de ces étapes.
Tout d'abord, comme pour les algorithmes précédents, nous convertissons l'itération sur les objets par un procédé récursif. Nous commençons par ajouter le premier objet dans la liste des états donnés, puis nous répétons le processus sur la liste résultant de cet ajout et sur les objets restants. Là encore, nous avons besoin d'une spécialisation pour mettre un terme à la récursivité lorsque tous les objets ont été considérés. Finalement, ce patron est déclaré comme suit :
/**
* \brief Étend une liste d'états en ajoutant itérativement les objets d'une
* liste donnée. Le résultat est une définition de type nommée result.
* \param StateList Les états à étendre.
* \param ItemList Les objets à traiter.
*/
template<typename StateList, typename ItemList>
struct dp_kp_loop;
/**
* \brief Spécialisation pour le cas où il n'y a aucun objet à traiter. Le
* résultat est la liste d'états donnée en paramètre.
* \param StateList Les états à étendre.
*/
template<typename StateList>
struct dp_kp_loop<StateList, empty_list>
{
typedef StateList result;
};
/* Déclaration complète */
/**
* Le résultat est obtenu en ajoutant les objets de ItemList::tail dans la liste
* des états obtenus par l'ajout de ItemList::head à partir de
* StateList. L'ajout des objets de ItemList::tail se fait par une utilisation
* répétée de ce patron de classe.
*/
template<typename StateList, typename ItemHead, typename ItemTail>
struct dp_kp_loop< StateList, type_list<ItemHead, ItemTail> >
{
typedef typename
dp_kp_loop
<
typename add_item
<
ItemHead,
StateList
>::result,
ItemTail
>::result result;
};Par construction, le profit du dernier état de la liste construite par add_item<> est maximal. Finalement, nous retournerons donc cet état comme solution du problème. Nous écrivons alors le patron ci-dessous pour récupérer le dernier type d'une liste de types :
/**
* \brief Récupère le dernier élément d'une liste de types.
* \param TypeList La liste de types.
*/
template<typename TypeList>
struct last_type;
/** Spécialisation pour le cas où la liste contient plus d'un élément. */
template<typename Head, typename Tail>
struct last_type< type_list<Head, Tail> >
{
typedef typename last_type<Tail>::result result;
};Bien sûr, l'utilisation de ce patron n'a de sens que si la liste des états contient au moins un état. Cette situation correspond à la spécialisation permettant de mettre fin à la récursivité :
/** Spécialisation pour le cas où la liste contient un seul élément. */
template<typename Head>
struct last_type< type_list<Head, empty_list> >
{
typedef Head result;
};Tous les éléments sont maintenant présents pour effectuer le calcul de la valeur optimale des solutions d'un problème de sac à dos. Il ne nous reste plus qu'à définir un patron de classe prenant en paramètre la capacité du sac et la liste des objets, et qui définit comme résultat un des états ayant le profit maximum parmi ceux obtenus par la boucle d'ajout des objets. Ce patron sera le suivant :
/**
* \brief Une classe qui résout un problème de sac à dos en utilisant
* l'algorithme de programmation dynamique par listes. Le résultat est
* une déclaration de type nommée result, renommant une instanciation du
* patron de classe state<>.
* \param Capacity La capacité du le sac.
* \param ItemList Les objets sur lesquels nous faisons une sélection.
*
* Le résultat est obtenu en ajoutant les objets de ItemList dans une liste
* initiale d'états. Cette liste ne contient qu'un état où le profit est nul et
* la capacité disponible est Capacity. L'ajout des objets se fait via le patron
* de classe add_items<>, définissant une liste d'états atteignables avec tous
* les objets de ItemList. Par construction, le dernier état de cette liste a le
* plus grand profit. Il est sélectionné pour définir le résultat.
*/
template<unsigned int Capacity, typename ItemList>
struct dp_kp
{
typedef typename
last_type
<
typename dp_kp_loop
<
// la liste initiale d'états contient un unique état ayant un profit nul
// et dans lequel toute la capacité est disponible. Nous partons de cet
// état pour ajouter...
type_list<state<0, Capacity>, empty_list>,
// ...tous les objets.
ItemList
>::result
>::result result;
};Le code ci-dessous illustre l'utilisation du patron dp_kp<> pour calculer la valeur du problème présenté dans la section 1.1. Pour plus de lisibilité, les poids et la capacité du sac ont été divisés par 100 000 :
int main()
{
// définition de la liste des objets
typedef
type_list< item<4, 40>,
type_list< item<4, 52>,
type_list< item<2, 27>,
type_list< item<5, 68>,
type_list< item<5, 80>,
type_list< item<3, 62>,
type_list< item<3, 63>,
type_list< item<2, 53>,
type_list< item<1, 56>,
type_list< item<1, 59>,
empty_list
>
>
>
>
>
>
>
>
>
>
kp;
std::cout
<<"profit optimal : "
<< dp_kp<160, kp>::result::profit
<<" pour une capacite de : "
<< dp_kp<160, kp>::result::remaining_capacity
<<"\n";
return 0;
}4. Expérimentations numériques▲
Nous avons implémenté quatre algorithmes pour résoudre des problèmes de sac à dos : une procédure récursive avec un équivalent en métaprogrammation et l'algorithme de programmation dynamique, aussi avec un équivalent en métaprogrammation. Pour évaluer les performances de ces quatre approches, nous allons les appliquer à un ensemble d'instances du problème initial.
Bien sûr, le temps d'exécution des versions utilisant la métaprogrammation sera constant, étant donné que le calcul est effectué durant la compilation. Par conséquent, nous mesurerons le temps de compilation pour ces versions. Ainsi, nous pourrons situer les performances du compilateur.
Les instances ont une taille variant de 5 à 15, puis de 15 à 50 par pas de 5. Les profits et les poids sont générés aléatoirement dans l'intervalle [1 ; 1 000] et la capacité du sac est dans tous les cas égale à la moitié de la somme des poids des objets. Enfin, 10 instances ont été générées pour chaque taille.
L'ordinateur sur lequel les évaluations sont effectuées est doté d'un processeur Intel Pentium M cadencé à 2 GHz, ainsi que de 1,5 Gio de mémoire. Le compilateur g++ est utilisé, dans sa version 4.3.
Les temps de compilation et d'exécution moyens, maximaux et minimaux parmi les dix instances d'une taille donnée sont présentés par la courbe ci-dessous. La programmation dynamique par liste ayant résolu chacune des instances en moins d'un dixième de seconde, les temps ne sont pas reportés dans ce graphique :
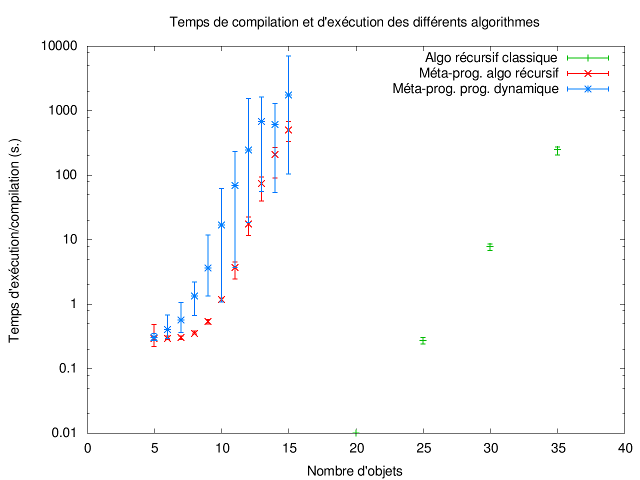
Sans surprise, les temps de compilation des versions métaprogrammation des algorithmes sont bien plus grands que ceux des algorithmes compilés. Cependant, il est étonnant de constater que pour les versions metaprogrammation l'algorithme récursif est bien plus rapide que la programmation dynamique. Cela s'explique en deux points. Tout d'abord, la programmation dynamique produit de nombreuses instanciations des patrons de classes, ce qui est coûteux à maintenir pour le compilateur. D'autre part, avec l'algorithme récursif en métaprogrammation le compilateur ne résout pas deux fois le même problème, comme en programmation classique. Quand il a résolu le type solve_kp<W, L> une fois pour une capacité W donnée et une liste L d'objets, il réutilisera cette solution à chaque fois que ce même type réapparaîtra dans l'exploration. En fait, le compilateur fait implicitement ce que l'on demande à la programmation dynamique.
En particulier, nous avons observé de grandes variations des temps de résolution avec la programmation dynamique en métaprogrammation en fonction du nombre de patrons utilisés.
5. Conclusion▲
Dans cet article, nous avons proposé deux métaprogrammes permettant de résoudre des problèmes de sac à dos durant la compilation du programme. Nous avons tout d'abord présenté le problème, puis deux algorithmes permettant de calculer la valeur optimale des solutions de ses instances. Nous avons ensuite présenté des techniques de métaprogrammation utilisant des patrons de classes et nous avons implémenté les deux algorithmes initiaux en utilisant ces techniques.
Nous avons ensuite évalué les performances des algorithmes sur plusieurs instances du problème. Il ressort que l'approche de la programmation dynamique est la moins performante dans le cas de la métaprogrammation, alors qu'elle surpasse l'approche récursive dans leurs versions compilées.
Les algorithmes implémentés ne calculent que la valeur optimale des solutions, sans indiquer quels objets sont effectivement choisis ou non. Il pourrait être intéressant d'étendre les structures pour prendre en compte cette information.
Enfin, il serait intéressant de produire une implémentation de la programmation dynamique utilisant moins de patrons de classe, afin d'évaluer l'influence de ce paramètre sur le temps de compilation. Une évaluation de ce temps avec d'autres compilateurs serait aussi la bienvenue.
Je remercie en particulier koala01, Alp et 3DArchi pour leurs nombreux retours et commentaires, ainsi que eusebe19, pixelomilcouleurs et Wachter pour la relecture de cet article.
L'archive meta-kp.tar.gz contient les programmes présentés dans cet article, ainsi que les instances de test.
6. Références▲
- R. E. Bellman. Dynamic Programming. Princeton University Press, 1957.
- S. Martello et P. Toth. Knapsack Problems : Algorithms and Computer Implementations . John Wiley & sons, 1990. (pdf).